| Course Concepts | |||
|---|---|---|---|
| Section | Section Title | Self Assessment1 | |
| ISL | 3.2 | Multiple Linear Regression | 3.0 |
| ISL | 3.3 | Other Considerations in the Regression Model | 3.0 |
| ISL | 3.4 | The Marketing Plan | 3.0 |
| ISL | 3.5 | Comparison of Linear Regression with K-Nearest Neighbors | 2.5 |
| ISL | 4.1 | An Overview of Classification | 3.0 |
| ISL | 4.2 | Why Not Linear Regression? | 3.0 |
| ISL | 4.3 | Logistic Regression | 2.0 |
| ISL | 4.4 | Generative Models for Classification | 1.5 |
| ISL | 4.5 | A Comparison of Classification Methods | 2.0 |
| ISL | 4.6 | Generalized Linear Models | 2.0 |
| ISL | 5.1 | Cross-Validation | 2.0 |
| ISL | 5.2 | The Bootstrap | 2.5 |
| ISL | 6.1 | Subset Selection | 2.0 |
| ISL | 6.2 | Shrinkage Methods | 2.0 |
| ISL | 6.3 | Dimension Reduction Methods | 2.5 |
| ISL | 6.4 | Considerations in High Dimensions | 2.0 |
| ISL | 13.1 | A Quick Review of Hypothesis Testing | 3.0 |
| ISL | 13.2 | The Challenge of Multiple Testing | 2.0 |
| ISL | 13.3 | The Family-Wise Error Rate | 2.0 |
| ISL | 13.4 | The False Discovery Rate | 2.0 |
| ISL | 13.5 | A Re-Sampling Approach to p-Values and False Discovery Rates | 2.0 |
| DF | n/a | The Power Chapter | 2.0 |
| DF | n/a | Collect, Analyze, Imagine, Teach | 2.0 |
| DF | n/a | On Rational, Scientific, Objective Viewpoints from Mythical, Imaginary, Impossible Standpoints | 2.0 |
| DF | n/a | What Gets Counted Counts | 2.0 |
| DF | n/a | Unicorns, Janitors, Ninjas, Wizards, and Rock Stars | 2.0 |
| DF | n/a | The Numbers Dont Speak for Themselves | 2.0 |
| DF | n/a | Show Your Work | 2.0 |
| 1 Proficiency level ranges from 1 (low) to 3 (high). | |||
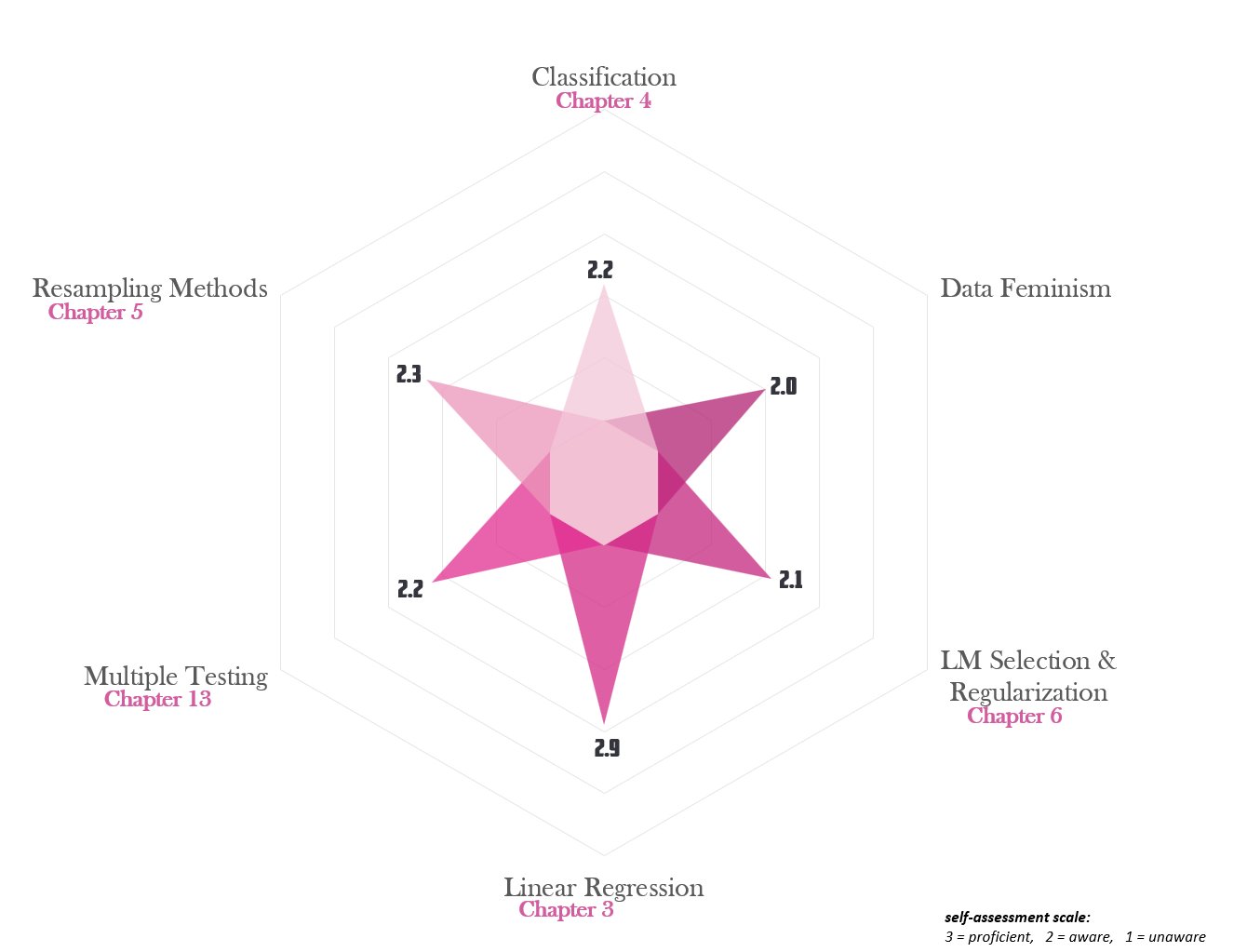
Current Level of Understanding
Statistical Modeling and Regression
Explanation of Assessment
Proficient Areas:
I marked items here as proficient because I have had repeated academic exposure and application of these concepts.
Linear regression:
I have a basic understanding of the underlying concepts, assumptions, and techniques involved in linear regression. I have completed assignments and projects that required implementing linear regression and analyzing the results.
- For example, in my final project last semester in CIS 631, I conducted an analysis using multiple linear regression. The project focused on evaluating the relationship between crime rates and the presence of cannabis dispensaries while controlling for socioeconomic factors. I collected relevant data, preprocessed it, and applied multiple linear regression to model the relationship. I carefully interpreted the results and drew meaningful conclusions based on statistical significance and the summary of my model’s output.
Overall, my proficiency in linear regression is based on a combination of theoretical knowledge gained through coursework, practical application in projects and assignments, and the ability to critically analyze and interpret the results obtained.
Aware Areas:
I marked these items as aware because I am familiar with the terms, but have limited practice applying the techniques.
Data Feminism:
My awareness here derives from a combination of the literature and media I consume, along with principles discussed in PSM 650 – “Ethical and professionalism” and CIS 631– “Data Mining”.
I’d like to note that I bought the audiobook version of Data Feminism over Memorial Day. I am finding it easier to digest the philosophy presented in that format.
Classification:
- I am familiar with the terms in classification and the types of ways we can categorize data as ordinal, nominal and categorical. I’ve used K-nearest neighbors algorithms, and decision trees in CIS 500 – “Fundamentals of Software Practice.” I recognize I need to more exposure and practice here.
Linear Model Selection and Regularization:
Looking over the section titles of this ISL chapter, I see I have had some practice with dimension reduction using principle component analysis but have not taken the opportunity to apply this methodology outside of a lab exercise.
Additionally, as part of your Stat 518 – Statistical Computing and Graphics with R, I deployed bootstrapping methodology in the final project.
Multiple Testing:
I have had exposure to these concepts both professionally, when communicating market research and survey results and academically, particularly in Stat 216. I feel most comfortable with hypothesis testing , understanding type 1 and type 2 errors, and evaluating and explaining p-values.
I marked this one as aware verses proficient because I feel I need more reinforcement learning in this area.